GLM-5.2:为长程任务而生(官方技术博客全译)
GLM-5.2:为长程任务而生
本文译自 Z.ai 官方博客 GLM-5.2: Built for Long-Horizon Tasks,译文保持原文严谨性,所有数据与 benchmark 名称均按原文保留。
我们正式发布 GLM-5.2——为长程任务(long-horizon tasks)打造的最新旗舰模型。相比上一代 GLM-5.1,它在长程任务能力上实现了大幅跃升,并首次将这一能力落地在扎实的 100 万 token 上下文之上。GLM-5.2 的全新能力包括:
- 扎实的 1M 上下文(Solid 1M Context): 一份稳定的百万级 token 上下文,能够稳固地支撑长程工作。
- 灵活 effort 等级的进阶编码能力(Advanced Coding with Flexible Effort): 更强的编码能力,提供多种思考 effort 等级以平衡性能与延迟。
- 改进的架构(Improved Architecture): 我们提出 IndexShare,在每四层稀疏注意力层中复用同一个 indexer,在 1M 上下文长度下将单 token 的 FLOPs 降低 2.9×。我们还改进了 GLM-5.2 的 MTP 层用于投机解码(speculative decoding),将接受长度(acceptance length)最多提升 20%。
- 纯粹开源(Pure Open): 采用 MIT 开源协议——无地域限制,技术上无国界访问。
支撑长程任务,首先要让长上下文在工程上真正可用:模型必须能在长而杂乱的编码 Agent 轨迹中保持质量,而不仅仅是能”塞进”更多 token。1M 上下文宣称容易,但在真实工程压力下保持可靠却难得多。为此,我们针对编码 Agent 场景大幅扩展了 1M 上下文训练,覆盖大规模代码实现、自动化研究、性能优化和复杂调试。最终得到的长上下文系统不仅覆盖面广,而且执行扎实:是支撑持续工程工作的实用底座。
这一能力也反映在 GLM-5.2 于三个长程编码 benchmark 上的表现。FrontierSWE 衡量一个 Agent 能否在数小时到数十小时的尺度上完成开放式技术项目,涵盖系统优化、大规模代码构建和应用 ML 研究。在该 benchmark 上,GLM-5.2 仅落后 Opus 4.8 1%,同时领先 GPT-5.5 1%、领先 Opus 4.7 11%。在 PostTrainBench 上——每个 Agent 分配一块 H100 GPU,以它通过后训练能把小模型改进多少来评估——GLM-5.2 超过 Opus 4.7 和 GPT-5.5,仅次于 Opus 4.8 排名第二。在 SWE-Marathon 上——一个涵盖构建编译器、优化 kernel、开发生产级服务等任务的超长程软件工程 benchmark——GLM-5.2 仍有成长空间,落后 Opus 4.8 13%,但同样仅次于 Opus 系列排名第二。在这三个 benchmark 上,GLM-5.2 都是排名最高的开源模型,表明其 1M 上下文已经转化为切实的长程交付能力。
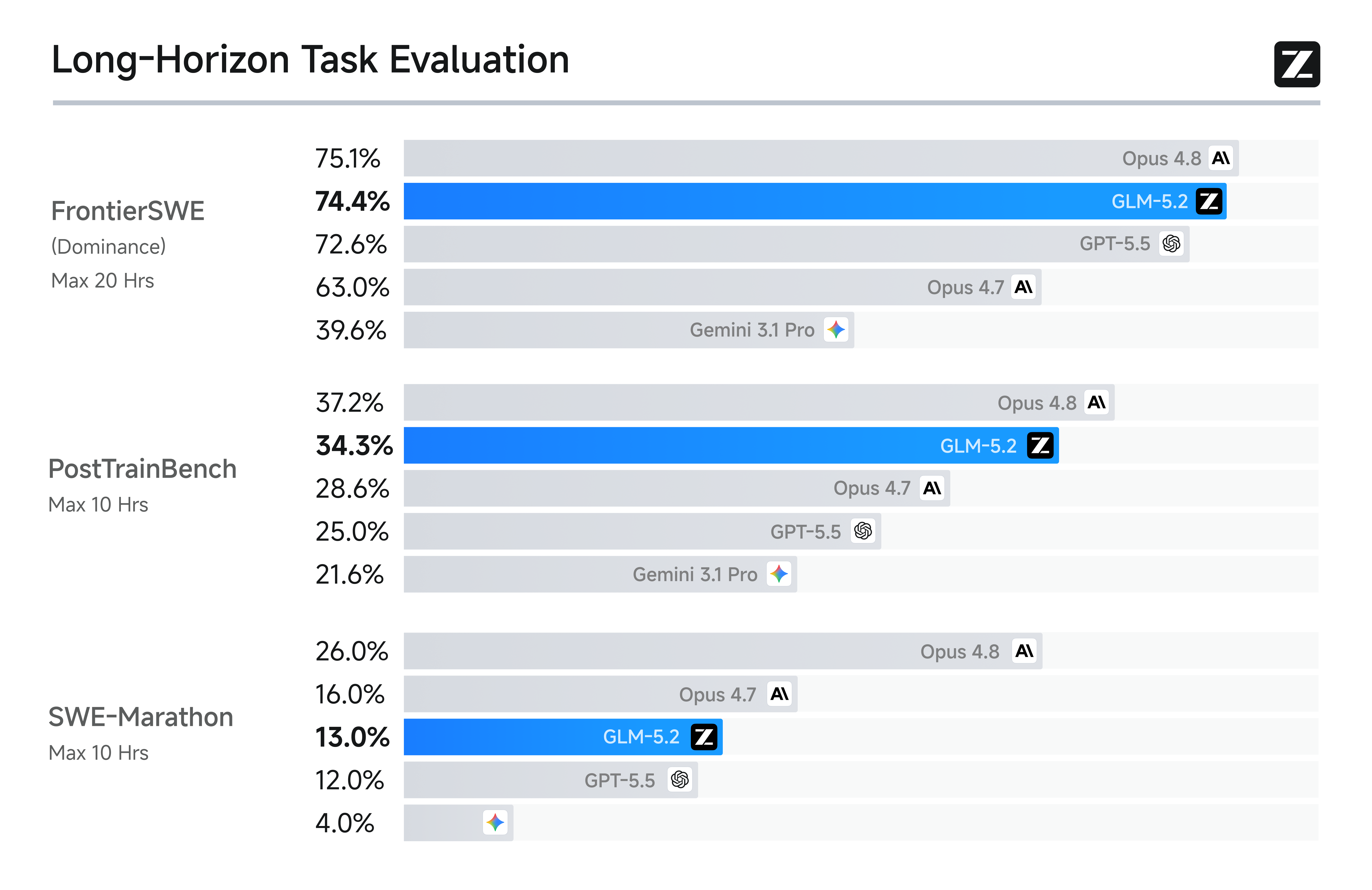
图1:长程任务评估(Long-Horizon Task Evaluation)。GLM-5.2 在三项 benchmark 上均为排名最高的开源模型。
在标准编码 benchmark 上,GLM-5.2 是最强的开源模型,相比 GLM-5.1 有大幅提升:Terminal-Bench 2.1 上 81.0 vs. 63.5,SWE-bench Pro 上 62.1 vs. 58.4。它也大幅缩小了与闭源前沿的差距——在 Terminal-Bench 2.1 上(81.0)距离 Claude Opus 4.8(85.0)仅几个百分点之内——同时领先于 Gemini 3.1 Pro。
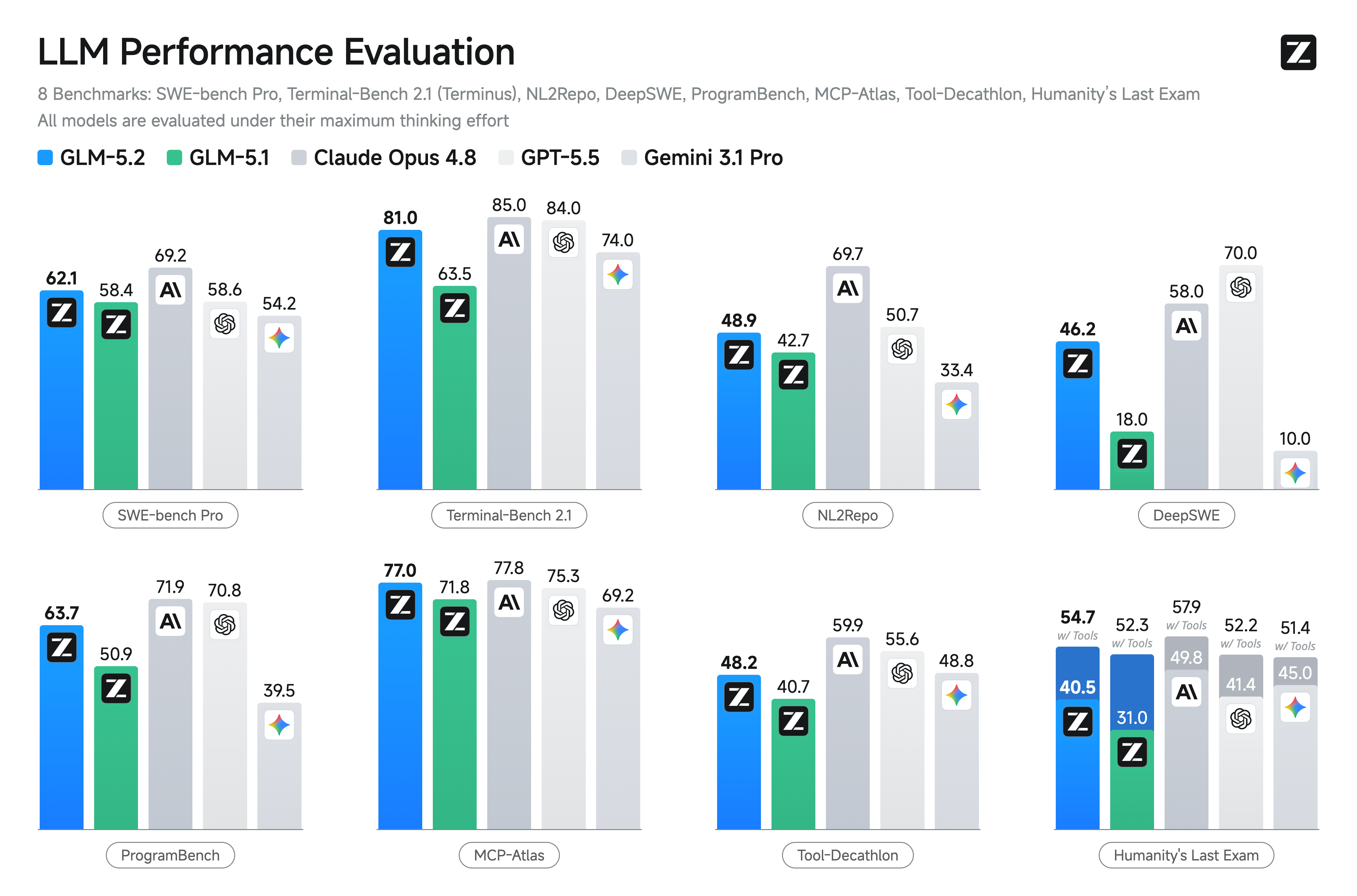
图2:标准编码 benchmark 对比。GLM-5.2 在 Terminal-Bench 2.1 上距离闭源前沿 Claude Opus 4.8 仅数点之差。
GLM-5.2 还引入了 effort 等级控制,让用户可以显式地在模型能力与任务执行速度、计算成本之间取得平衡。如图所示,在相近的 token 预算下,GLM-5.2 的 Agentic 编码性能显著强于 GLM-5.1,其能力在相近 token 消耗下大致介于 Claude Opus 4.7 与 Claude Opus 4.8 之间。此外,Max effort 等级允许用户在困难任务需要更高性能时投入更多算力,进一步拓展模型的编码能力。这一设计让用户在使用 GLM-5.2 完成编码任务时拥有更大灵活性,可针对不同场景选择最合适的推理模式。
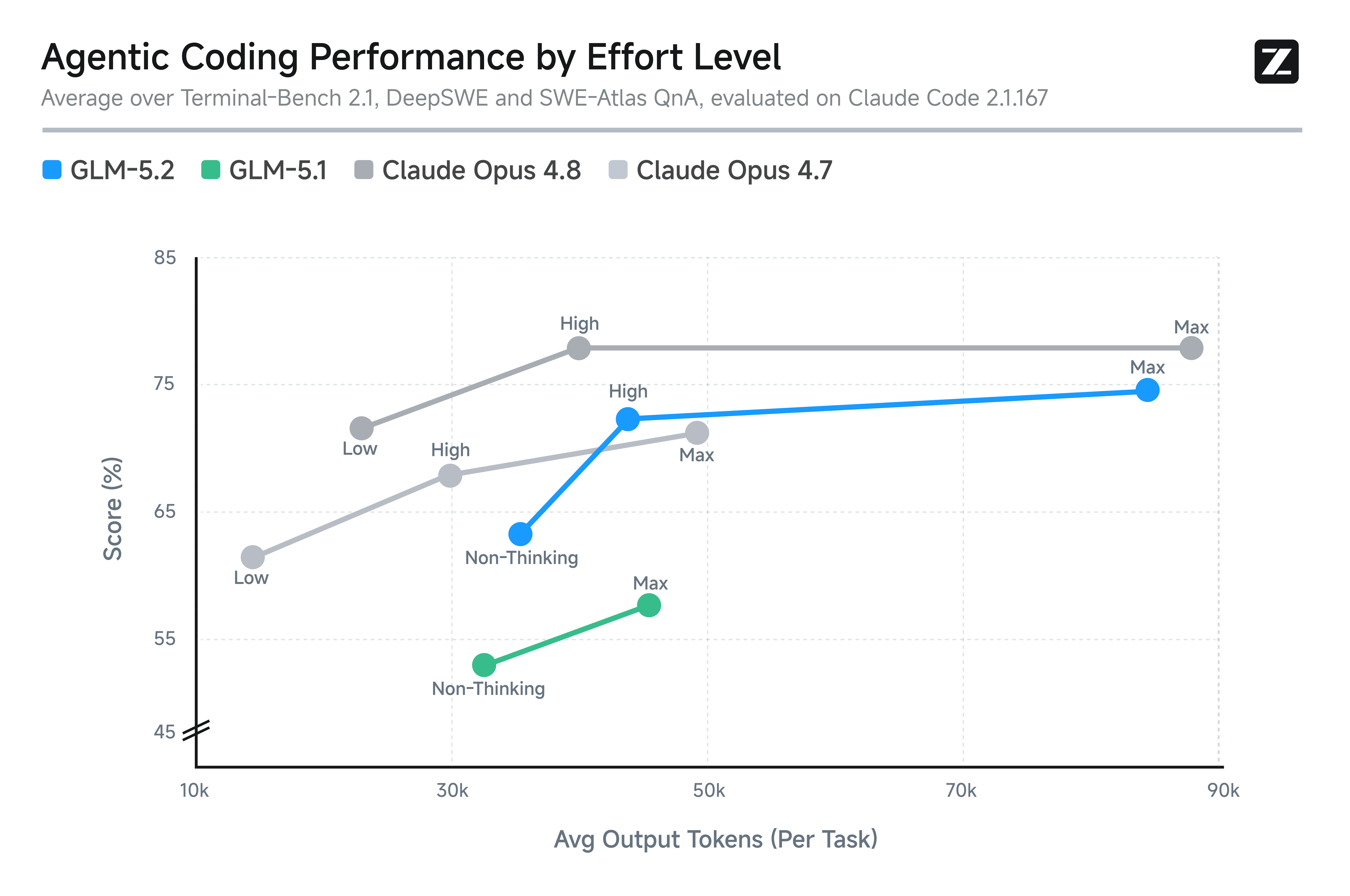
图3:Agentic 编码性能随 effort 等级变化。GLM-5.2 能力大致介于 Opus 4.7 与 Opus 4.8 之间,Max 等级可进一步释放潜力。
百万上下文的架构(Architecture for 1M Context)
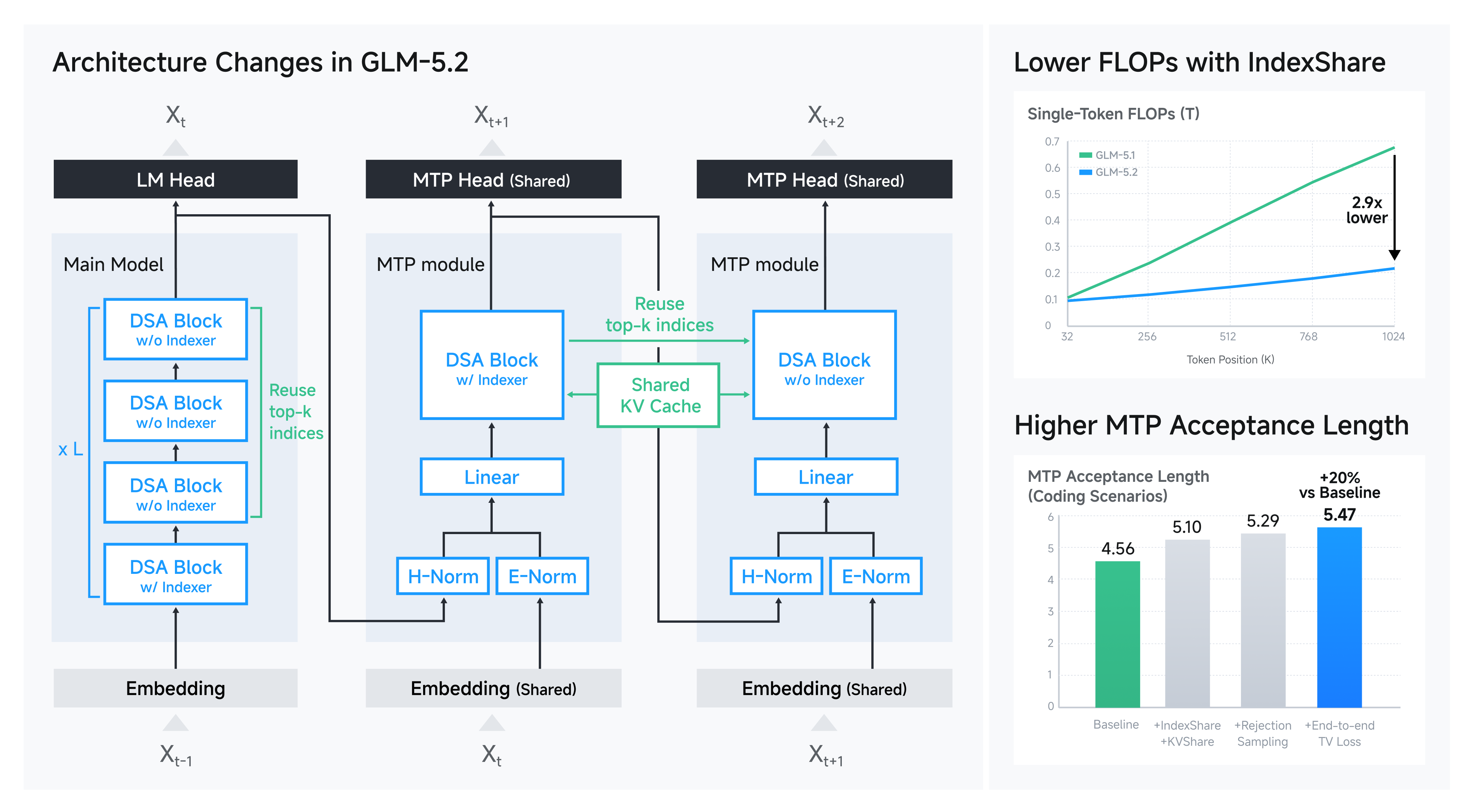
图4:架构改进概览。IndexShare 在 1M 上下文下显著降低 FLOPs,同时保持性能。
用于 DSA 的 IndexShare
为支撑 1M 上下文长度,GLM-5.2 中我们应用 IndexShare 来降低 DSA 中 indexer 的计算成本。具体而言,在 GLM-5.2 中,每 4 层 transformer 共享一个轻量级 indexer。该 indexer 放置在 4 层中的第一层,其 topk 索引被后续 4 层复用。这减少了 3/4 层中 indexer 点积和 topk 运算的计算量。GLM-5.2 从中期训练(mid-training)阶段就以 128K 序列长度配合 IndexShare 进行训练,在更少计算量下于长上下文 benchmark 上超越了 GLM-5.1。
带 IndexShare 与 KVShare 的 MTP
我们改进了 GLM-5.2 的 MTP 层用于投机解码,有两个目标:1)最小化 MTP 层作为 draft 模型的成本;2)最大化投机解码的接受率。
对于第一个目标,我们同样在 mtp 层应用 IndexShare。在多步 MTP 中,indexer 放置在第一步,其 topk 索引被所有后续步骤复用。然而,与 backbone 不同的是,不同 mtp 步骤的输入 token 是不同的。如下图所示,如果我们复用第 1 步的 topk 索引,那么第 2 步的 hidden states 只能 attend 到第 1 至第 4 个位置的 KV,而不能 attend 到第 5 个位置。我们将证明这一性质恰好能帮我们实现第二个目标——消除 GLM-5.1 mtp 层中训练与推理的不一致。
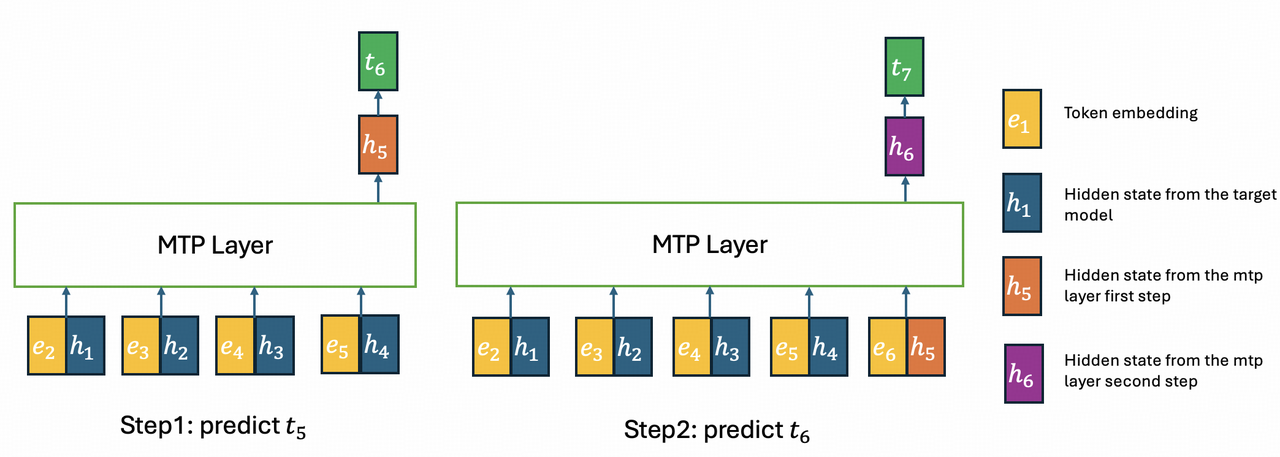
图5:两步 MTP 层推理示意。上图为推理过程:第 1 步与训练一致,第 2 步引入 IndexShare 使 KV cache 仅来自目标模型,消除训练-推理差异。
在上图中,我们展示了一个两步 MTP 层的推理过程。在第 1 步,推理与训练一致,所有 hidden states 都来自目标模型。然而在第 2 步,h₁₋₄ 来自目标模型,而 h₅ 来自 mtp 层。因此,h₅ 的 KV cache 是由目标模型计算的 kv₁₋₄ 与由 mtp 层计算的 kv₅ 混合而成。而借助 IndexShare,h₅ 的 KV cache 仅包含 kv₁₋₄,全部来自目标模型的 hidden states。在训练时,我们复用第一个 mtp 步骤的 kv cache 和 topk 索引。注意,与 GLM-5.1 相同,不同 MTP 步骤的参数也是共享的。此外,受 arxiv 2606.12370 启发,我们为投机解码引入了拒绝采样(rejection sampling),并使用端到端 TV loss 进行训练。
下表展示了各项技术按接受长度(acceptance length)在编码场景上的消融实验。实验中我们使用 GLM-5.1 的 backbone 和训练数据。训练和推理的 MTP 步数均设为 7。与基线相比,最终 MTP 层的接受长度提升了 20%。
| 方法(Method) | 接受长度(Acceptance Length) |
|---|---|
| Baseline(基线) | — |
| + IndexShare + KVShare | — |
| + Rejection Sampling(拒绝采样) | — |
| + End-to-end TV Loss(端到端 TV 损失) | +20% |
高效服务 1M 上下文长度
随着 GLM-5.2 将最大上下文长度从 200K 扩展到 1M token,编码工作负载预计会显著向更长 prompt 倾斜。这使得推理的主要瓶颈从计算转移到 KV-cache 容量、长上下文 kernel 开销以及 CPU 侧开销。尽管新的 GLM-5.2 架构降低了单 token 的计算 FLOPs,但并未成比例地降低单 token 的 KV-cache 体积。因此,在有限 GPU 资源下支撑更长上下文、更高并发和更高 token 吞吐,成为推理引擎优化的核心挑战。
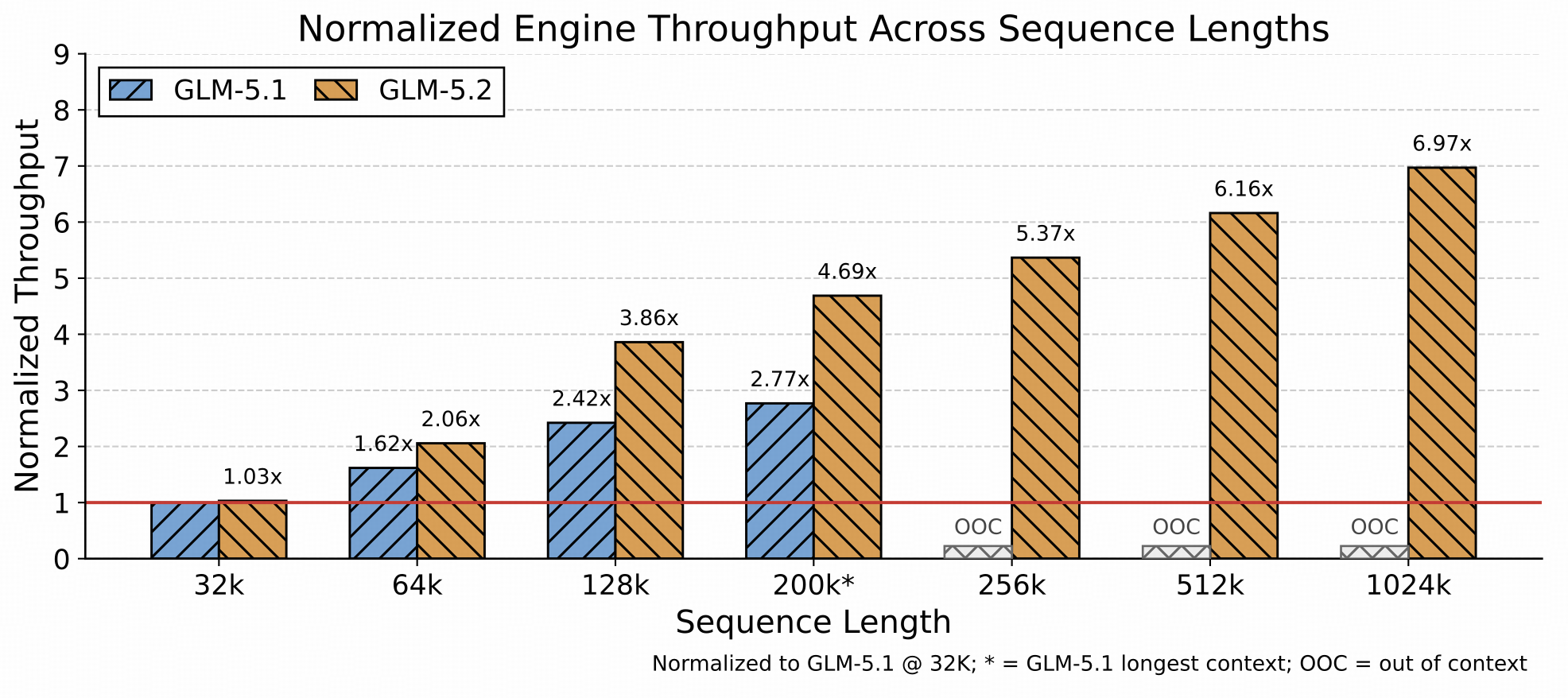
图6:推理引擎优化效果。GLM-5.2 随上下文增长获得越来越大的吞吐优势,在长上下文推理场景中展现出更强可扩展性。
为应对这一挑战,我们沿三个方向优化推理引擎。第一,在 LayerSplit 基础上,引入更细粒度的内存管理与并行策略,以提升 KV-cache 容量,为超长上下文请求提供更多可用缓存空间。第二,优化那些成本随上下文长度增长的 kernel,并更好地与缓存传输流水线协同,最小化缓存传输对 prefill 和 decode 性能的影响。第三,优化 CPU 侧的缓存管理、请求调度与运行时执行路径,减少 GPU 执行流水线中的气泡,提升端到端吞吐。如图所示,GLM-5.2 随上下文长度增长获得越来越大的吞吐优势,在长上下文推理场景中展现出更强的可扩展性。
slime:支撑 Agentic RL
GLM-5.2 的 Agentic RL 后训练涉及更大规模、跨更多领域、执行模式更复杂的任务。异构数据与任务需要在统一的训练流程中组织起来,而长程交互、工具调用、子任务分解和多轮环境反馈,都对 rollout 与训练编排提出更高要求。为支撑这一过程,slime 作为从训练到大规模推理 rollout 的集成基础设施层。它支持多种训练与任务组织模式,包括白盒 rollout、黑盒 rollout、紧凑轨迹(compact trajectory)和子 Agent 工作流,使同一套系统能够扩展到更大、更复杂的 RL 和 OPD 训练负载。在 GLM-5.2 的后训练过程中,我们使用 slime 框架开展并行 OPD 训练,将十余个专家模型高效融合进最终模型。整个 OPD 训练流程耗时约两天,展现出极高的训练效率。
Agentic RL 也对系统资源和推理基础设施提出更高要求。slime 为推理系统提供了高度开放且灵活的接口:训练侧可以以不同形式接入推理服务,并灵活适配不同的并行策略、路由策略、PD 分离(prefill-decode disaggregation)配置与部署形态。与此同时,RL rollout 期间积累的配置经验、调度策略与优化路径,可在生产服务阶段复用并进一步打磨,让训练侧与服务侧相互强化。这构建起一条从后训练到生产部署更直接的路径。配合灵活的训练-推理资源组织与 KV-cache FP8,slime 为 GLM-5.2 的大规模 Agentic RL 训练提供了关键基础设施支撑,进一步提升了系统效率、rollout 吞吐与大规模推理并发。
带反作弊的长程任务 RL
长程任务的 RL(RL for Long-Horizon Tasks)。 对 GLM-5.2 而言,长程任务会产生长得多的执行轨迹,一旦一条超长轨迹被压缩(compaction)切分成多条子轨迹,同一 prompt 下的不同 rollout 就会产生数量不等、长度差异巨大的可训练轨迹。因此,我们从基于组的优化转向基于 critic 的 PPO 形式——从单条 rollout 中学习,依靠 critic 来估计 token 级的 advantage,而非依赖组间相对比较。这种单 rollout 形式天然契合压缩机制,因为它对一条 prompt 产生多少条轨迹、它们的相对长度如何都不加约束:我们把压缩纳入训练,将所有被压缩的子轨迹都作为可训练轨迹,并用 token 级 loss 来应对它们之间的长度不平衡。
编码 Agent 中的反作弊(Anti-Hack in Coding agents)。 编码 RL 尤其容易受到奖励作弊(reward hacking)的影响,因为奖励通常是可验证的通过/失败信号。我们发现 GLM-5.2 比 GLM-5.1 展现出更多潜在的作弊行为。这让验证信号易于优化,却无法真正提升模型的基础能力。Agent 可能读取受保护的评测产物、从参考答案或上游 commit 中复制答案内容,或在 GitHub 相关任务中直接拉取目标源码。例如,Agent 可能会去抓取远程代码仓库里的原始文件来获取答案;甚至更隐蔽的链式泄露——先在工作目录下搜索名称含 hidden 的隐藏评测文件,读取其中的秘密测试用例(secret_cases),再把它当作参数传给求解脚本一次性跑通全部用例。
这些行为会虚高奖励、污染训练信号,需要一套清晰的机制将真正的任务求解与捷径区分开。为此,我们为 RL 训练和评测都引入了反作弊模块。检测流程分两个阶段:首先由基于规则的过滤器以高召回率捕获潜在作弊,然后由 LLM 判官检查这些被标记动作的意图以保持高精确率。我们采用在线策略,在每一步监控工具调用。一旦检测到作弊,系统会拦截该调用并返回虚假信息作为结果。重要的是,这一在线守卫允许模型在被抓到一次作弊动作后仍继续 rollout。通过处理具体的无效行为而非拒绝整条轨迹,这种方式有助于避免 rollout 被突然中断可能引发的训练不稳定和模型崩溃。
完整 Benchmark 表(Full Benchmark Table)
| GLM-5.2 | GLM-5.1 | Qwen3.7-Max | MiniMax M3 | DeepSeek-V4-Pro | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | |
|---|---|---|---|---|---|---|---|---|
| 推理(Reasoning) | ||||||||
| HLE(w/ Tools) | 49.8* | 41.4* | 52.2* | 51.4* | ||||
| CritPt | ||||||||
| AIME 2026 | ||||||||
| HMMT Nov. 2025 | ||||||||
| HMMT Feb. 2026 | ||||||||
| IMOAnswerBench | ||||||||
| GPQA-Diamond | ||||||||
| 编码(Coding) | ||||||||
| SWE-bench Pro | 62.1 | 58.4 | ||||||
| NL2Repo | ||||||||
| DeepSWE | ||||||||
| ProgramBench | ||||||||
| Terminal-Bench 2.1(Terminus-2) | ||||||||
| Terminal-Bench 2.1(Best Reported Harness) | ||||||||
| 82.7(Claude Code) | ||||||||
| 69(Claude Code) | ||||||||
| 78.9(Claude Code) | ||||||||
| 83.4(Codex) | ||||||||
| 70.7(Gemini CLI) | ||||||||
| FrontierSWE(Dominance as of 26/6/16) | ||||||||
| PostTrainBench | ||||||||
| SWE-Marathon | ||||||||
| Agentic | ||||||||
| MCP-Atlas(Public Set) | ||||||||
| Tool-Decathlon |
* 指其在完整数据集(full set)上的得分。原表完整数值请参见 Z.ai 官方博客 的交互式表格;上表保留了原文列出的所有评测项与已公开的代表性分数(GLM-5.2 Terminal-Bench 2.1 为 81.0、SWE-bench Pro 为 62.1 等)。
开始使用 GLM-5.2
通过 GLM Coding Plan 使用 GLM-5.2
在你熟悉的编码 Agent 中使用 GLM-5.2 —— ZCode、Claude Code、OpenCode 等。详见 docs.z.ai/devpack/overview。
GLM Coding Plan 订阅用户: 我们已向所有 Coding Plan 用户推出 GLM-5.2。你现在就可以将模型名更新为 "GLM-5.2" 来启用(在 Claude Code 中使用 GLM-5.2[1m] 启用 1M 上下文长度)。你还可以根据任务选择不同的思考 effort 等级——High 或 Max。作为我们最强的模型,GLM-5.2 在高峰时段按 3× 消耗配额、非高峰时段按 2× 消耗。作为持续到 9 月底的限时促销,非高峰使用按 1× 计费。(高峰时段为每日 14:00–18:00 UTC+8 北京时间。)
偏好图形界面?我们提供 ZCode——一款由 GLM-5.2 驱动的桌面 Agent,具备用于长程任务的 /goal、SSH 远程开发与移动端控制。
特别优惠: 在 ZCode 内通过 Coding Plan 使用 GLM-5.2,6 月 30 日前享 1.5× 有效配额。
立即开始:z.ai/subscribe
在 Z.ai 上与 GLM-5.2 对话
GLM-5.2 现已上线 Z.ai。
本地部署 GLM-5.2
GLM-5.2 的模型权重已在 HuggingFace 与 ModelScope 公开。本地部署方面,GLM-5.2 支持的推理框架包括 transformers、vLLM、SGLang、xLLM、ktransformers。
脚注(Footnote)
- Humanity’s Last Exam(HLE)及其它推理任务: 我们使用的采样参数为
temperature=1.0、top_p=0.95。评测时最大生成长度为163,840token。默认报告纯文本子集;带 * 的结果来自完整数据集。对 AIME、HMMT 和 IMOAnswerBench,每道题用如下系统提示词评测:Your response should be in the following format:\nExplanation: {your explanation for your final answer}\nExact Answer: {your succinct, final answer}\nConfidence: {your confidence score between 0% and 100% for your answer}.
我们使用 GPT-5.5(medium)作为判官模型。对 HLE-with-tools,使用最大 300,000 token 上下文长度,不采用任何上下文管理策略。 - SWE-Bench Pro: 我们使用 OpenHands 运行 SWE-Bench Pro 套件,并采用定制的指令 prompt。设置:
temperature=1、top_p=1、max_new_tokens=32k,400K 上下文窗口。 - NL2Repo: 使用
temperature=1.0、top_p=1.0、max_new_tokens=48k,400K 上下文。为防止作弊,使用基于规则和基于 LLM 的双重判定来阻止恶意行为(如未授权的 pip 或 curl 操作)。 - DeepSWE: 使用官方 pier 评测框架和 mini-swe-agent harness(
temperature=1.0、top_p=1.0、timeout=2h,400K 上下文)。每个任务在隔离容器中求解,配置为 2 CPU、8 GB RAM,无互联网访问。 - ProgramBench: 使用 Claude-Code 2.1.156 评测 ProgramBench(200 实例),参数为
temperature=1.0, top_p=1.0, max_tokens=64000, max_turns=2000, sample_timeout=6h, reasoning_effort=max,400K 上下文窗口。每个实例在(4 CPU、8 GB RAM)沙箱中运行,禁用互联网访问。 - Terminal-Bench 2.1(Terminus 2): 使用 Terminus-2 框架评测 Terminal-Bench 2.1,参数
parser=json、timeout=4h、temperature=1.0、top_p=1.0、max_new_tokens=48k、max_episodes=500,256K 上下文窗口。资源上限为 4 CPU、8 GB RAM。 - Terminal-Bench 2.1(Claude Code): 在 Claude Code 2.1.167 中评测,参数
temperature=1.0, top_p=0.95, max_new_tokens=131072。我们通过透明代理将 max_new_tokens 覆盖为 128k,绕过 64k 的 CLI 上限以恢复CLAUDE_CODE_MAX_OUTPUT_TOKENS的可配置性。我们移除了挂钟时间限制,同时保留每任务的 CPU 和内存约束。分数为 5 次运行的平均。 - MCP-Atlas: 所有模型均在 500 任务的公开子集上以思考模式评测,每任务 10 分钟超时。我们使用 Gemini-3.0-Pro 作为判官模型。
- Tool-Decathlon: 使用官方评测服务,max_token 设为 128K。
- FrontierSWE: 评测由 Proximal 执行,1M 上下文长度、最高 effort 等级、128K 最大输出 token。Dominance 分数截至 2026/06/16。
- PostTrainBench: 评测由 PostTrainBench 执行,1M 上下文长度、最高 effort 等级、128K 最大输出 token。
- SWE-Marathon: 评测由 Abundant AI 执行,1M 上下文长度、最高 effort 等级、128K 最大输出 token。
本文译自 Z.ai 官方博客,原文链接及模型权重:GitHub · HuggingFace · 文档。译文版权归原文作者所有,转载请注明出处。